Toolbox to run Decoded Neurofeedback (DecNef) or Functional Connectivity Neurofeedback (FCNef) experiments.
The code is Matlab-based, and was developed under Matlab ver. 8.2 (R2013b), and should be functional with any later version of Matlab (but no official testing has been done).
The toolbox code is available at a secure server of ATR Brain Information Communication Research Laboratory. The laboratory head and the head of the neuroimaging facilities should fill, sign and submit the consent form by email to the server administrator (open-decnef@atr.jp) for access.
Selecting Functional Connectivity (FC) for the ASD biomarker and assessing its generalization capability.
The procedure for selecting relevant FCs, training a predictive model and assessing its generalization ability is carried out as a sequential process of 9×9 nested feature-selection and leave-one-out cross-validation (see Schematic Figure). In each leave-one-out (LOO) cross-validation (CV) fold, all-but-one subjects are used to train a Sparse Logistic Regression (SLR) classifier, while the remaining subject is used for evaluation. SLR has the ability to train a logistic regression model, while objectively pruning FCs that are not useful for the purpose of classifying ASD. Before training SLR, it is necessary to reduce the input dimension to some extent and simultaneously remove the effects of NVs that may cause catastrophic over-fitting. Therefore, prior to LOOCV, nested feature selection was performed using L1-SCCA. L1-SCCA identifies the latent relationships between FCs and various attributes of each individual, including the diagnostic label, available demographic information, and imaging conditions. By selecting FCs that have a connection with a canonical variable related only to the “Diagnosis” label and not to NVs, we aim to reduce the interferential effects of NVs. The feature (FCs) selection procedure is similar to 9×9 nested cross-validation, with the difference being that the test set is never used for validation or feature (FCs) selection (see Schematic Figure). In this way, L1-SCCA is trained on different subsamples of the dataset, in order to increase the stability of the selected features. The “test set” of the outer loop feature selection (FS) process is kept as a testing pool for LOOCV, whereas the 9 folds of the inner loop FS are used to select features. Consequently, the LOOCV folds that belong to the same testing pool of the outer loop FS share the same reduced features. In the inner loop FS, the L1-SCCA hyperparameters λ1 and λ2 were varied independently between 0.1 and 0.9 (λ1 ≤ λ2, assuming more sparsity for the FCs) with a step of 0.1. For each instance of L1-SCCA, we found the canonical variables connected only with the label “Diagnosis” and kept the features associated with those canonical variables.
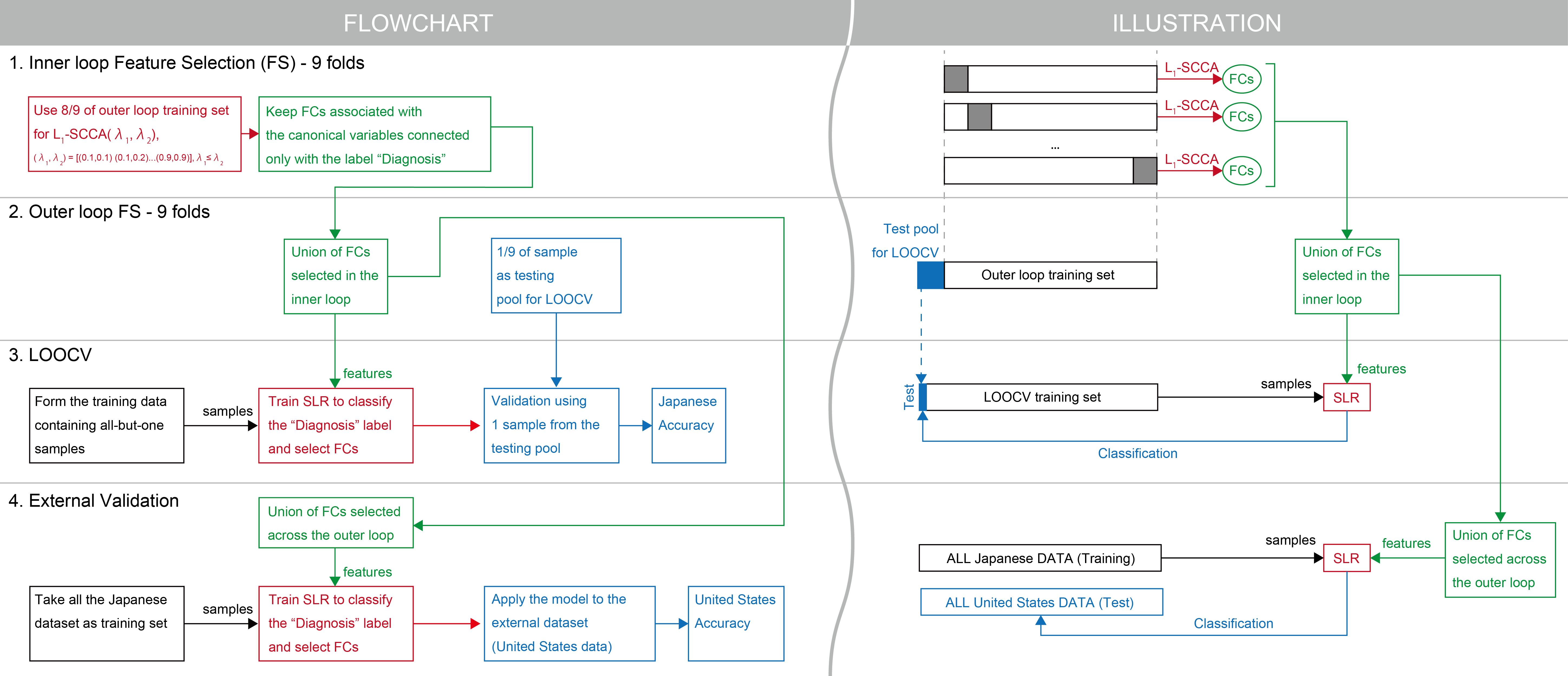
Description of the script that runs this procedure, based on the Schematic Figure steps [i]
[1] In each iteration of the inner loop (bm_nested_fs.m) feature selection (FS), 8/9 of the outer loop training set is used to train L1-SCCA with different hyper-parameters (bm_cca.m). Functional connectivity features (FCs) that are associated with the canonical variables connected only with the label “Diagnosis” are retained (bm_handle_cca_out.m). [2] In the outer loop FS, 1/9 of the samples is retained as testing pool for leave-one-out cross-validation (LOOCV), and the union of the FCs selected throughout the inner loop is derived (bm_handle_cca_out.m). [3] One sample is taken from the testing pool of the outer loop, and used as test set of LOOCV (bm_run_cv.m). The remaining samples are used to train SLR on the union of the FCs retained during the inner loop. This procedure is repeated for every sample in the testing pool of the outer loop. In this way, the test set of LOOCV is always independent from the dataset used to select features. [4] The union of the FCs selected across the outer loop is used to train the final SLR on the whole Japanese dataset, and validated using an external cohort dataset (bm_loso_std_ext.m). In conclusion, nested feature selection is used to remove nuisance FCs, LOOCV is used to quantify generalizability on the Japanese dataset, and the external validation is used to quantify generalizability on the independent dataset. The results are evaluated by bm_eval.m.
Code availability
The classification code (FcBm) and the correlation matrix data used in the present study are available at a secure server of ATR Brain Information Communication Research Laboratory. If you request access for the code and the data, please check the paragraph at the bottom.
The code for Sparse Logistic Regression (SLR) can be obtained at https://bicr.atr.jp/~oyamashi/SLR_WEB.html.
Program codes that enables to reproduce our simulations about effects of DecNef training on neuronal activities.
In our recent paper (to be detailed after formal publication), we conducted simulations that aimed to explore what is changed at a neuronal level as a result of neurofeedback computed based on measured fMRI signal patterns at a voxel level. For readers who are interested in details of the simulations and reproduction of the results on their computer, we have uploaded program codes (written in Matlab) to the following page. Please note that the codes has been uploaded in its development state according to reviewers’ request, and that it will be cleaned later on.
Code availability
The DecNef simulation code is available at a secure server of ATR Brain Information Communication Research Laboratory. Please contact the server administrator (asd-classifier@atr.jp) for access.Please use the format below when you request access to the code.
***********************************
Name:
Company/University name:
E-mail address:
Request access to: FcBm or DecNef simulation
***********************************
Program code of deface (face-masking) for anatomical MRI images
To avoid identifying individual participant by reconstruction of face surface from the structural MRI data of our datasets, we performed face-masking calculation. This code removes the subject’s face from the MRI structure image (NIfTI format: .nii). This is written in MATLAB and internally uses SPM8 and mri_deface.